В одной из предыдущих статей я описывал человеко-понятные урл - ЧПУ URL и разное отношение поисковиков к ним. В данной статье хотелось бы рассмотреть само понятие УРЛ, так как оно является основополагающим для всего Интернета.
URL (Uniform Resource Locator) - переводится с английского как Унифицированный указатель ресурса, или Единообразный (универсальный) локатор ресурса, т.е. это путь, по которому можно найти любой файл и каталог в сети Интернет.
URL адрес страницы сайта состоит из следующих элементов: протокол://полное доменное имя/(папка(и))/имя ресурса (файла). В расширенном варианте УРЛ может выглядеть так:
схема://логин:пароль@хост:порт/(папка(и))/имя ресурса (файла)?параметры#якорь
Основные параметры Урл:
- в качестве схемы выступает обычно какой-нибудь протокол, обычно это http(s), ftp и множество других (skype, nfs)
- логин-пароль нужны для прохождения одного из способов авторизации пользователя на сервере. Если авторизации не требуется, эти параметры не указываются
- хост - полное доменное имя или IP-адрес компьютера в сети. Например, для Яндекса - это Yandex.ru
- порт - на каком порту сервера будет производиться подключение к нему. В большинстве случаев, данный параметр не указывается, т.к. по умолчанию подразумевается порт 80, которым обычно пользуются браузеры. Попробуйте к любому URL адресу сайта подставить ":80", ничего нового не произойдёт - будет совершён переход на адрес "без порта". Например http://www.google.ru:80 перекинет на http://www.google.ru.
- далее идёт или сразу имя файла (например, page.php), или сначала 1 и более каталогов, а потом имя файла. Если имя файла отсутствует, то открывается т.н. индексный файл - index.php (index.html, index.jsp и множество других расширений).
- после имени файла могут указываться дополнительные параметры - после знака вопроса (?). Между параметрами ставится знак амперсанда (&). К примеру, выглядеть это может так: http://www.bing.com/account/web?sh=5&ru=%2f. Самих параметров может быть много, они имеют вид переменная=значение и обрабатываются на сервере с помощью языков серверного программирования
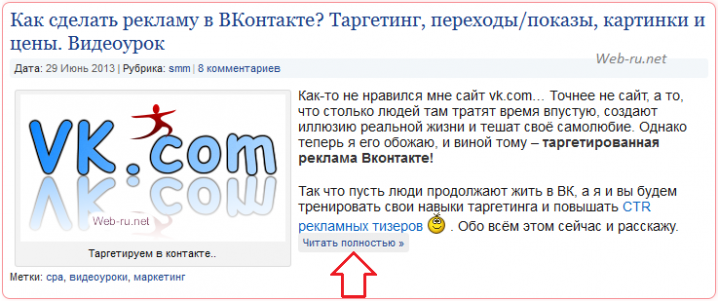
- якорь в URL подставляется после решётки (#) и указывает на элемент открываемой страницы, причём браузер обычно автоматически производит прокрутку до того html-элемента, id которого равно якорю. Например, на созданных на WordPress сайтах при клике на "Читать далее"как раз это и происходит:
Допустимые символы URL
В URL адресе допустимы только латинские буквы, арабские цифры и ограниченный набор знаков препинания:
- дефис (-),
- подчёркивание (_)
- точка (.)
Также возможны запятые (,) и точки с запятой (;), но используются они редко и обычно кодируются, как и все остальные символы (русские буквы, пробелы и т.п.). Яркий пример закодированных урл'ов - статьи Википедии - http://ru.wikipedia.org/wiki/%D0%95%D0%B6.
Правила кодирования нелатинских букв (в т.ч. кириллицы) и прочих не допустимых символов URL: сначала буква кодируется в UTF-8 (кодировку Unicode) - получается 2 байта из каждого символа. Затем каждый из этих байтов преобразуется в шестнадцатиричную систему счисления и перед ним ставится знак процента (%), получается что-нибудь такое: %D0%95%D0%B6 (по-русски будет "еж"). Недопустимые знаки препинания кодируются так:

Среди УРЛ выделяют относительные и абсолютные, а также статические и динамические URL адреса страниц сайта. Об этом будет рассказано в следующих статьях.